Vector Database (Cơ sở dữ liệu Vector) đang nổi lên như một công nghệ nền tảng không thể thiếu, thúc đẩy khả năng hiểu và phản hồi của các hệ thống Trí tuệ Nhân tạo (AI) tiên tiến như ChatGPT, Google Gemini. Khác biệt hoàn toàn so với các cơ sở dữ liệu truyền thống, Vector Database không chỉ lưu trữ dữ liệu mà còn lưu trữ ý nghĩa của dữ liệu đó dưới dạng số học.
Bài viết này sẽ đi sâu giải thích Vector Database là gì?, cách nó hoạt động qua khái niệm Vector và Embedding, và cuối cùng là những ảnh hưởng sâu sắc của nó đối với các lĩnh vực như AI và SEO (Tối ưu hóa công cụ tìm kiếm).
I. Vector và Embedding là gì?: Cách AI “Hiểu” Thế Giới
Để hiểu Vector Database, trước tiên chúng ta cần nắm rõ hai khái niệm cốt lõi: Vector và Embedding. Chúng chính là ngôn ngữ số hóa mà AI sử dụng để diễn giải mọi thứ từ văn bản, hình ảnh, đến âm thanh.
1. Vector là gì?
Trong toán học và vật lý, Vector là một đại lượng có hướng và độ lớn, thường được biểu diễn bằng một tập hợp các con số (tọa độ) trong một không gian.
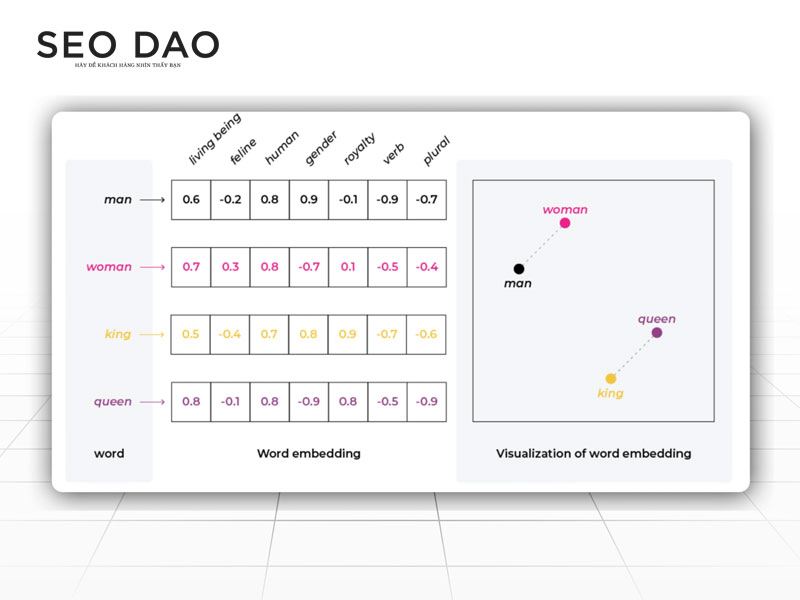
Trong bối cảnh AI, khi bạn gửi một câu hỏi hay một câu lệnh, hệ thống không xử lý từng từ dưới dạng chữ cái. Thay vào đó, nó chuyển đổi dữ liệu đầu vào thành một chuỗi các con số, được gọi là vector.
Hãy hình dung một cách trực quan:
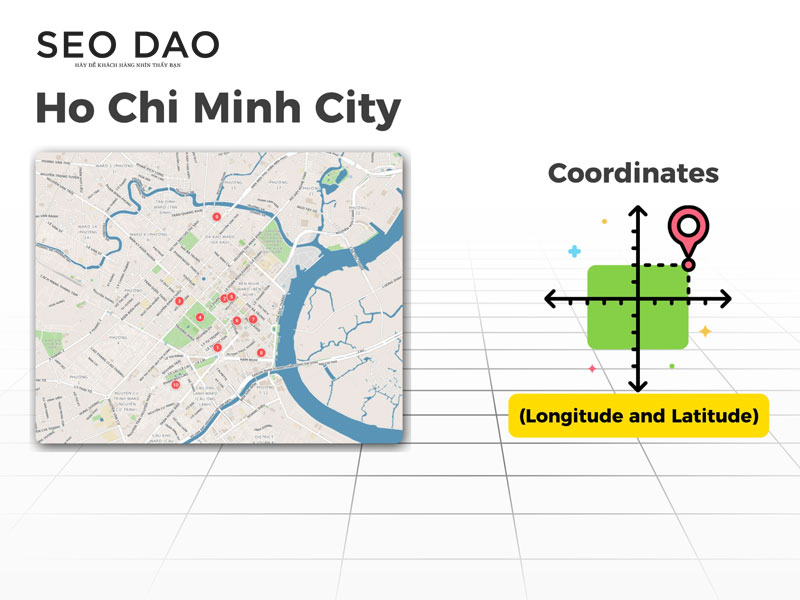
- Bản đồ TP.HCM: Mỗi địa điểm (nhà bạn, công ty, chợ Bến Thành) được xác định bằng một tọa độ (kinh độ [x] và vĩ độ [y] ). Tọa độ này chính là một vector (chẳng hạn, [x, y]) trong không gian hai chiều.
- Không gian ngữ nghĩa: AI làm điều tương tự, nhưng trong không gian nhiều chiều hơn rất nhiều (ví dụ: 768 chiều hoặc 1536 chiều). Mỗi từ, cụm từ, hay cả câu sẽ được định vị bằng một tập hợp các con số trong không gian đa chiều này. Tập hợp các con số này chính là Vector biểu diễn ý nghĩa.
2. Embedding là gì?
Embedding (Phép nhúng) là một loại vector đặc biệt, được tạo ra bởi các mô hình AI (như mô hình ngôn ngữ lớn – LLM) với mục đích mô tả và mã hóa ý nghĩa ngữ nghĩa của dữ liệu.

Đây là quá trình biến đổi dữ liệu phi cấu trúc (văn bản, ảnh, âm thanh) thành dạng số hóa mà AI có thể tính toán và so sánh:
- Văn bản (Ví dụ: “Hôm nay trời đẹp”) —> Vector số
- Ảnh (Ví dụ: Hình ảnh một con mèo) —> Vector số
- Âm thanh (Ví dụ: Một đoạn nhạc) —> Vector số
Nói ngắn gọn: Embedding chính là vector biểu diễn ý nghĩa của dữ liệu trong không gian số.
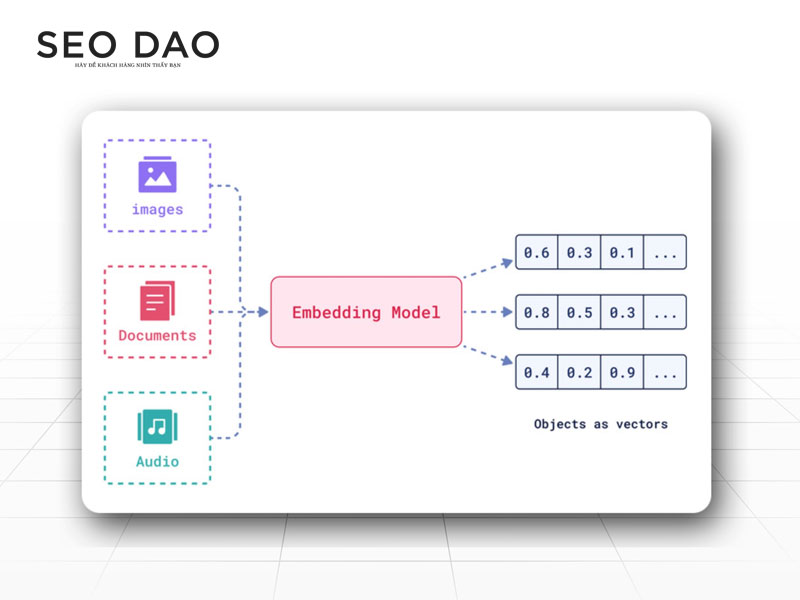
Sở dĩ gọi là “embedding” vì các mô hình AI đã “nhúng” (embed) ý nghĩa phức tạp, đa chiều của dữ liệu vào một chuỗi số có thể quản lý được.
3. Các Ứng Dụng Nền Tảng Của Embedding
Embedding chính là “nền móng” của mọi ứng dụng AI hiện đại, bao gồm:
- Semantic Search (Tìm kiếm ngữ nghĩa): Thay vì tìm kiếm dựa trên từ khóa khớp chính xác (như SQL truyền thống), hệ thống tìm kiếm dựa trên Embedding cho phép tìm kiếm theo ý nghĩa thực sự của câu hỏi.
- Retrieval-Augmented Generation (RAG): Kỹ thuật quan trọng giúp các mô hình ngôn ngữ lớn (LLM) truy xuất thông tin liên quan từ cơ sở dữ liệu bên ngoài (thông qua Embedding) để tạo ra phản hồi chính xác và đáng tin cậy hơn, tránh việc “bịa đặt” (hallucination).
- Recommendation Systems (Hệ thống Gợi ý): Tìm kiếm vector của sản phẩm/nội dung tương tự với những gì người dùng đã thích để đưa ra gợi ý liên quan.
- Clustering và Deduplication: Nhóm các dữ liệu có ý nghĩa giống nhau (clustering) hoặc tìm và loại bỏ nội dung trùng lặp (deduplication) một cách hiệu quả.
II. Vector Database: Giải Pháp Lưu Trữ và Truy Vấn Ngữ Nghĩa (Semantic Search)
Sau khi dữ liệu đã được chuyển đổi thành các Embedding Vector, chúng cần một nơi đặc biệt để lưu trữ và quan trọng hơn là để được truy vấn một cách hiệu quả. Đó là lúc Vector Database ra đời.
1. Vector Database Là Gì?
Vector Database (Cơ sở dữ liệu Vector) là một loại hệ thống cơ sở dữ liệu chuyên biệt, được thiết kế tối ưu hóa để lưu trữ, quản lý và tìm kiếm các Vector Embeddings với tốc độ cực cao trên quy mô lớn (hàng triệu, hàng tỷ vector).
Khác biệt cốt lõi:
| Cơ sở dữ liệu Truyền thống (SQL, NoSQL, MongoDB) | Vector Database (Pinecone, Weaviate, Milvus) |
| Lưu trữ dưới dạng văn bản, bảng, JSON, Key-Value. | Lưu trữ dưới dạng các Vector số (mảng số nhiều chiều). |
| Tìm kiếm dựa trên từ khóa khớp chính xác, các điều kiện logic (WHERE, LIKE…). | Tìm kiếm dựa trên khoảng cách và độ tương đồng giữa các vector. |
| Truy vấn tương đồng ngữ nghĩa cực kỳ chậm hoặc không thể thực hiện. | Cho phép tìm kiếm các vector giống nhau nhất (tương đồng về ý nghĩa) chỉ trong mili giây. |
2. Tại sao Cần Vector Database Thay Vì Database Truyền Thống?
Các Vector Embedding thường là các mảng số rất dài (ví dụ: 1536 con số cho mỗi Embedding).
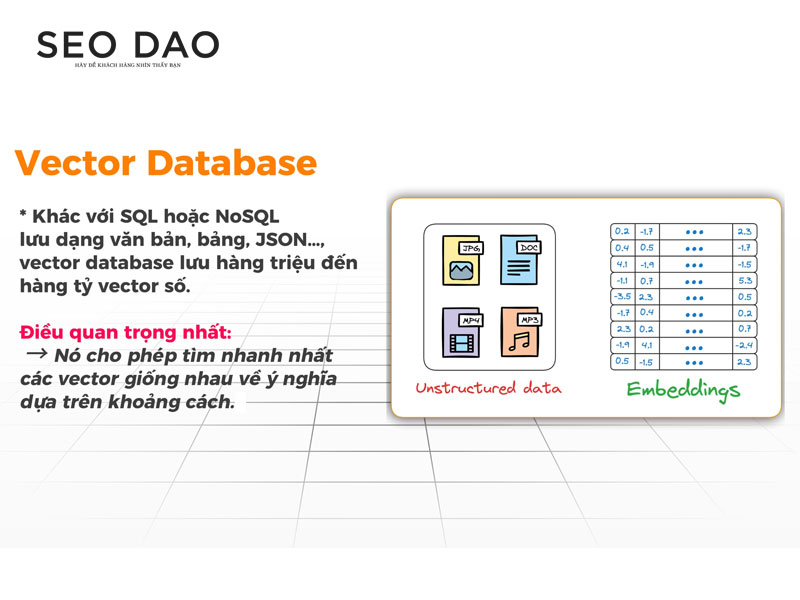
- Nếu cố gắng lưu trữ và tìm kiếm các vector này trong MySQL hoặc MongoDB bằng cách tính toán khoảng cách Euclidean hoặc Cosine Similarity, hệ thống sẽ trở nên cực kỳ chậm khi lượng dữ liệu lớn.
- Vector Database sử dụng các thuật toán tìm kiếm láng giềng gần nhất gần đúng (Approximate Nearest Neighbors – ANN) như HNSW, IVFFlat, thay vì tìm kiếm chính xác (Exact Nearest Neighbors).
Chìa khóa: Các thuật toán ANN cho phép Vector Database đánh đổi một chút độ chính xác nhỏ để đạt được tốc độ tìm kiếm nhanh gấp hàng trăm lần, ngay cả khi xử lý hàng tỷ điểm dữ liệu. Đây là điều kiện tiên quyết để xây dựng các ứng dụng AI tương tác thời gian thực.
3. Cách Hoạt Động Của Vector Database Trong Ứng Dụng AI (RAG)
Quy trình Vector Database hỗ trợ AI trong một ứng dụng Semantic Search/RAG diễn ra như sau:
- Chuyển đổi Dữ liệu: Các tài liệu, bài viết, hình ảnh của bạn được chuyển thành Vector Embeddings bằng mô hình AI.
- Lưu trữ: Các Vector Embeddings này được lưu trữ trong Vector Database.
- Truy vấn (Query): Người dùng nhập câu hỏi (Ví dụ: “Cách tốt nhất để tối ưu tốc độ website là gì?”).
- Vector hóa Truy vấn: Câu hỏi của người dùng được mô hình AI chuyển thành một Vector truy vấn V_{query}.
- Tìm kiếm Tương đồng: Vector Database nhận V_{query} và sử dụng thuật toán ANN để tìm kiếm và trả về N Vector gần V_{query} nhất (tức là những đoạn văn/thông tin có ý nghĩa liên quan nhất).
- Tạo Phản hồi: Những thông tin tương đồng (dạng văn bản gốc) được gửi đến Mô hình Ngôn ngữ Lớn (LLM) như ChatGPT.
- Phản hồi Cuối cùng: LLM tổng hợp thông tin và tạo ra câu trả lời chi tiết, chính xác dựa trên dữ liệu cụ thể, giúp LLM vượt ra khỏi giới hạn của dữ liệu huấn luyện ban đầu.
III. Ảnh Hưởng Của Vector Database Đối Với AI SEO
Sự kết hợp giữa Embedding và Vector Database đang tạo ra một cuộc cách mạng trong lĩnh vực SEO, chuyển từ kỷ nguyên tìm kiếm từ khóa sang kỷ nguyên AI SEO và Semantic SEO.
1. Thay Đổi Cơ Chế Xếp Hạng Nội Dung
Trong quá khứ, công cụ tìm kiếm xếp hạng dựa trên mật độ từ khóa và độ khớp chính xác. Ngày nay, AI SEO dựa trên sự hiểu biết ngữ nghĩa:
- Từ khóa —> Ngữ nghĩa: AI (như Google’s RankBrain, BERT, MUM) chuyển nội dung website thành Vector Embedding.
- Tương đồng ý nghĩa: Công cụ tìm kiếm không còn so sánh từ khóa của bạn với từ khóa trong truy vấn, mà so sánh Vector Embedding nội dung của bạn với Vector Embedding truy vấn của người dùng.
- Tối ưu hóa SEO: Điều này có nghĩa là việc nhồi nhét từ khóa không còn hiệu quả. SEO cần tập trung vào việc tạo ra nội dung đầy đủ, có thẩm quyền và đáp ứng trọn vẹn ý định tìm kiếm (Search Intent) của người dùng. Nếu nội dung của bạn có ý nghĩa tương đồng cao với hàng nghìn truy vấn khác nhau, Vector Embedding của nó sẽ được xếp hạng cao hơn.
2. Sự Trỗi Dậy Của AI Content và Cá Nhân Hóa
- Xây dựng Content Bank: Các doanh nghiệp đang dùng Vector Database để lưu trữ toàn bộ kiến thức, tài liệu, và nội dung marketing của mình. Khi cần tạo nội dung mới, AI truy vấn Vector Database để lấy thông tin liên quan, đảm bảo tính nhất quán và chính xác.
- Trải nghiệm Tìm kiếm Cá nhân hóa: Vector Database giúp AI hiểu lịch sử tìm kiếm, hành vi, sở thích của từng người dùng (cũng dưới dạng Vector) để so sánh với Vector của nội dung. Kết quả tìm kiếm và gợi ý sản phẩm/nội dung sẽ được cá nhân hóa sâu sắc, vượt xa các thuật toán lọc cơ bản.
Kết Luận
Vector Database không chỉ là một công cụ lưu trữ dữ liệu; nó là cơ sở hạ tầng trí tuệ cho mọi ứng dụng AI hiện đại. Bằng cách lưu trữ và tìm kiếm ngữ nghĩa (dưới dạng Embeddings) thay vì chỉ lưu trữ dữ liệu thô, nó đã mở ra cánh cửa cho:
- AI thông minh hơn: Qua RAG và Semantic Search, AI có thể truy xuất và trả lời dựa trên lượng kiến thức khổng lồ một cách chính xác và kịp thời.
- Trải nghiệm người dùng tốt hơn: Tìm kiếm và gợi ý được cá nhân hóa và sát nghĩa hơn bao giờ hết.
- Tối ưu SEO hiệu quả hơn: Buộc các nhà làm nội dung phải tập trung vào chất lượng và ý nghĩa ngữ nghĩa thay vì thủ thuật từ khóa.
Vector Database chính là mảnh ghép còn thiếu, biến khả năng xử lý ngôn ngữ và hình ảnh phức tạp của các mô hình AI thành các ứng dụng thực tế, tốc độ cao và đáng tin cậy.

Chào mọi người, mình là Thiện. Hiện tại mình đang là một SEO freelancer, với mong muốn chia sẻ kiến thức cũng như tư vấn rõ hơn những kinh nghiệm về SEO đến với các bạn SEO newbie cũng như khách hàng. Hy vọng sẽ giúp ích được cho mọi người trong việc nghiên cứu và triển khai các công việc liên quan đến SEO.